26 Sep 2023
RAG with Llama Index
Over an afternoon’s hacking, I’ve managed to setup a Large Language Model that implements a Retrieval Augmented Generation or RAG architecture locally. This enables LLMs to work on your own and up-to-date data without the need of retraining. In this post, I will be going through my initial implementation of the retrieval augmented generation or RAG systems.
Objective
The objective of this exercise is to setup and run a RAG implementation using LLMs with generally available hardware locally (no dedicated GPUs and no cloud!). I want to remove the barrier of expensive hardware and giving cloud providers more money and my information.
What is RAG?
Retrieval Augmented Generation or RAG for short allows the LLM to work with new data without the need of retraining. RAG has the following components:
- Vector Database (Elasticsearch, Pinecone, PostgreSQL Vector Plugin)
- Embedding Model (maybe different from the actual LLM)
- Large Language Model
General Flow
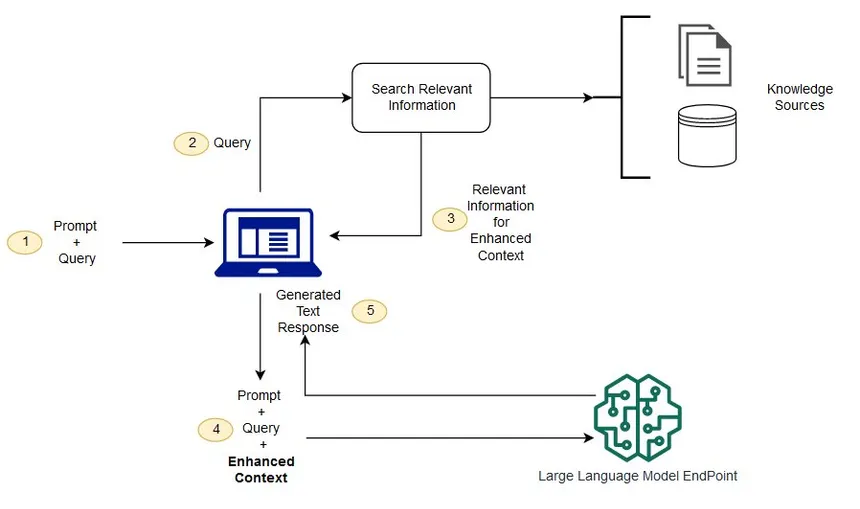
- Data Ingestion: Using an embedding model, the data will be ingested (texts in this case) into this database by converting them into vectors. As an example, the following sentece “A TIFF file is a raster format.” will be converted into
[0.211, 0.113, 0.44112, -0.1294] vector and this vector will be stored into the vector database. - Search and Retrieval: When a question comes in “Are TIFF files raster data?” the question will also be converted into a vector and the vector database will implement a clustering algorithm like approximate nearest neighbor, K-nearest neighbor, inverted index, etc.
- Summarization and Response: The returned results will be passed to the LLM and execute summarization task and thus generate the final output.
The Setup
Hardware
What I want to achieve in this experiment is to run the process without very expensive components like GPUs.
- CPU: Ryzen 4500u
- RAM: 16GB
- GPU: Integrated GPU (6 graphics cores)
- Operating: Ubuntu 22.04 running in WSL
- Swap: 0
Models and Data:
The models came from huggingface.co.
- Large Language Model: llama-2-7b-chat.Q4_0.gguf
- Embedding Model: sentence-transformers/all-mpnet-base-v2
- Data: QGIS 3.22 User Manual (1393 pages with files size of 50.9mb)
Libraries:
You may need to extra setup to configure LlamaCPP properly for your own hardware.
- Langchain
- LlamaCPP
- Llama Index
- PyPDF (to extract texts from PDFs)
The Experiment
I have created a notebook to go through the actual code here. In this post, I will just go through my observations of the processing flow.
- Data ingestion will take the longest part of the entire process and maybe resource intensive depending on the volume in terms of pages and files. This step will do the extraction from the source file, conversion of text into vector data, and store into the vector DB. In this exercise, it took about
12-15 mins to ingest a 1,393 page document and consumes about 6 GB of RAM for a 6 core machine. If your machine has more CPU cores or if the system has GPU this will be faster to run. 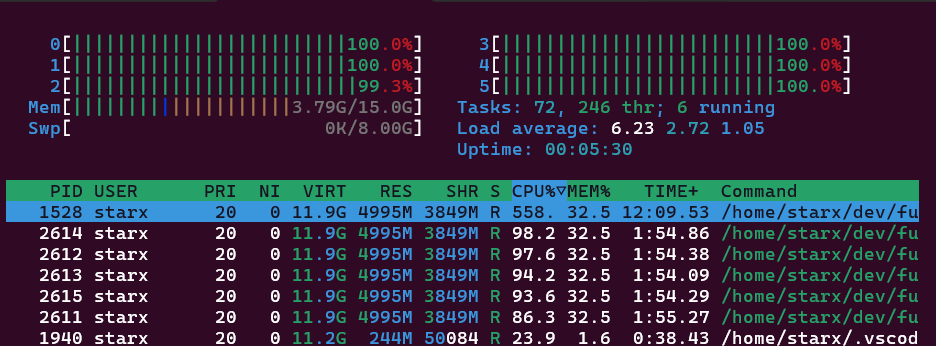
-
Depending on the model parameters like chunk_overlap, temperature, context_window, etc., the results may vary. There is a need to explore the sensitivity of each parameter in terms of generation performance.
- The inferencing section, executed about
2-3 mins. 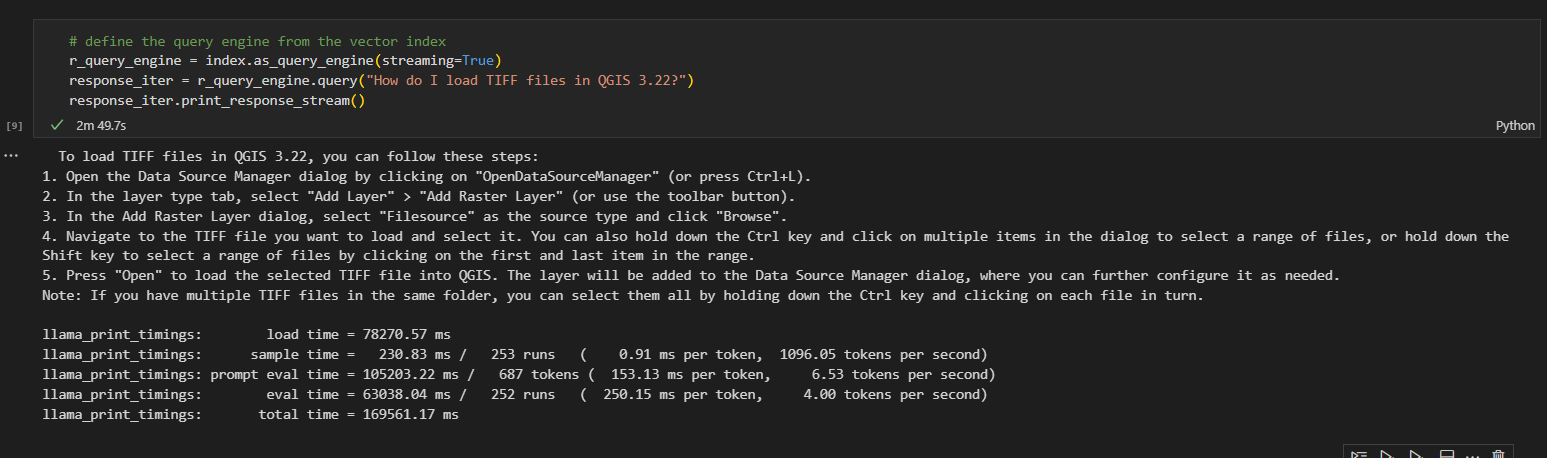
- The generated results have some errors and redundant steps.
Experiment Notes
- Returned results from the Vector DB (what are the paragraphs or sentences - do they make sense?)
- Prompt setup to implement summarization (from the returned results, what is the prompt used?)
- Model itself (since we are using a quantized model which uses int4 there maybe a loss of precision which affected the generated results. There is also how the model was trained where it will affect the quality of the results.)
Next Steps
- Try out other models more specialized to my use case which is more of an instruction type instead of chat.
- Play around the with parameters like chunk_overlap, temperature, context_window, etc.
- Extend the RAG system to not only focus in a vector setup but also with a mixture of text data (Bag of Words).
- Incorporate evaluation, where given multiple models, it will evaluate which output will be used as the main result or mix the outputs of these models. This is like ensemble learning where you a mixed of experts/models to generate a result.
- Create agents on-top of RAGs, where it will control a software using the outputs of the model. Given the outputs above, control QGIS to do the steps stated by LLM. I see the use case of e.g. I want to generate a flood model using the data in folder A where the model will follow papers X, Y, Z.
Notes, Takeaways, Opinions
- The outputs generated by the LLM may not be 100% accurate but for me this is enough to get me started or point me to the right direction. You will still need to evaluate the outputs if it makes sense.
- The barrier of going into the LLM space is still there but it is going down exponentially with better architecture, tooling, and ecosystem.
- For me, the better use for LLMs will be in the RAG type applications where every individual, company, or organization have their “secret” sauce. Hence, running it locally is of great value instead of offloading the system to an external provider.



